-- Updated 9-November-2008 with my apologies --
GNW writes,
I don't like any of the searches at Ancestry.com. It takes too much time to weed through all the results that have nothing that connects to your search. If you put in a name, dates, family members and they lived in that same county and state all of their lives, married there, and then died there, why should they start out with people who lived 1,000 miles from that location and was born 30 years after that person died? That is unforgiveable [sic] and simply put, STUPID.
Let me put together the reasons why this happens and tell you if something is being done about it.
 Everyone needs a good search strategy
Everyone needs a good search strategy
Ancestry's Relevance Ranked search works pretty much under the same assumptions as television's Dr. House:
- Everybody lies
- Everybody screws up
(Before I get into my discussion of ranked searching, let me say that if checking the Exact search box in the new search interface doesn't work as expected, you need to inform Ancestry.com. Find a current discussion on New Search on the official Ancestry.com Blog and leave a comment.)
The faulty world
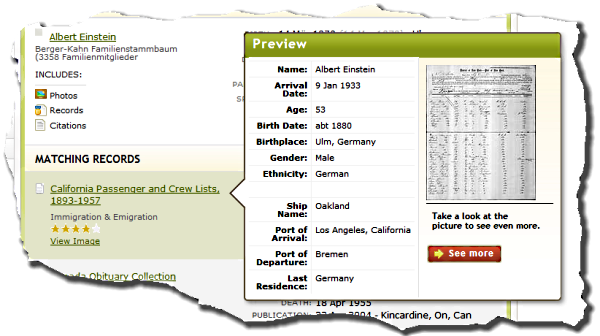
Put in the context of genealogical research, Dr. House's philosophy translates to, "take nothing for granted." Take for example, a census record. On any given page of the census somewhere you can find with 95% certainty at least one of the following faults:
- The census forms, questions or process gathered imprecise or ambiguous information.
- The respondent gave the enumerator incorrect information or avoided him altogether. Concepts of exactness in spelling and dating have not always been as strict as today, so the spelling of names could vary wildly. Neighbors were sometimes called upon to give information for those not at home. Respondents sometimes gave information for far away relatives they feared might not be counted.
- The enumerator wrote down incorrect information or didn't record everything and everyone that he was supposed to do. Sometimes fraudulent names and data were added.
- Often, a second copy of each census schedule was hand copied, introducing inadvertent errors. Sometimes, these copies are all that have survived for use today.
- While using the census records for their original purposes, names and information were overwritten, making some information illegible, some inconsistent with other information on the page and some incorrect.
- The census records were not always properly conserved and might no longer be legible or even extant. As ink fades, the lighter strokes of cursive handwriting can change the apparent spelling of names and places. Some were microfilmed out of focus and then the originals destroyed.
- The information on the census was incorrectly abstracted (i.e., extracted or indexed). Or one or more names or pages were skipped. Sometimes information vital to the interpretation of a census entry was written outside the normal fields or the abstraction software was not capable of capturing it.
- The electronic search index includes errors making some records impossible to find. It might exclude some names or groups of names. Sometimes information is incorrectly indexed because of faulty standardization or handling of abbreviations, names, dates and places.
- Sometimes you, the user, make typographical errors when typing information into search forms. And sometimes the targets of our searches show up in unexpected times and places.
A similar list can be produced for other types of records. Simply put, people screw up. A good searcher takes each of these errors into account and devices a search strategy accordingly. Have you ever used a successive term-dropping round-robin search to find a misindexed name? (Drop the first name, then the middle name, then the last name.) Have you ever used the successive term-dropping technique to find a person when you only had a vague guess about their location? But strip away the romance of performing dozens or hundreds of searches for one target record and the search strategy is pretty consistent. And pretty repeatable. And pretty mundane.
The ideal world
Wow! That's exactly what computers do better than humans. Lots and lots and lots of redundant tasks. So let's program the computer to do the ideal search strategy for us. I'm talking about the ideal world here, for a moment. Neither Ancestry.com nor anyone else has it right... yet.
Don't make me try all the nicknames, or even trust me to know or remember them all. Don't make me study out all the common name spellings. Don't make me study historical linguistics to find out how German pronunciation would affect phonetic name spellings. Let some expert somewhere do it once and let us all benefit from it. Don't make me explicitly search the census for family members to try and find my guy. The computer has my tree; do that search for me. Don't make me do successive term-dropping to account for the faults from the list above. Do it for me. Don't make me figure out every different name that a location was ever known by. Look them up and try them all for me. Hey, and while you're at it, can you account for common transliterations and other typos?
The real world
I'm happy to announce that Ancestry.com has been working on just such a feature for several years now. Some of the kinks are worked out. Some are not. It is called Relevance Ranked searching.
- The reason you get results 30 years after the death date is because the death date you entered might be wrong or the death date on results listed might be wrong.
- The reason you get results 1,000 miles away is because a location might be wrong.
- The reason you get results with different names is... well you get the picture.
So it is entirely normal to get results that don't match all of your criteria. That is by design. It is entirely normal to get way too many results. They are sorted from best to worst. Look through the results until your superior brain says, "I've reached the point where the quality of the results is less than what I am willing to wade through." Then let your superior brain zero in on a particular record collection or database. Or change the search criteria. Click the exact box on selected items. Then try another search. Gradually release the autopilot and take greater control of the search. But do it after you've let the ranked search take its best crack at it.
Ancestry.com has stated that they think their current algorithm has a big problem: it ranks results by how many search terms match but doesn't penalize non-matches. Kendall Hulet discussed that here and Anne Mitchell brought it up again in this comment. Will they be able to fix this problem?
What does your brain do differently when it says, "poppycock, that's not a match!" versus "There he is! In Kansas?" If they can figure that out, then they can fix this problem.
 Dear GNW
Dear GNW
I hope that explains why you get ranked results that don't match the input criteria. As you can see, that is sometimes good and sometimes bad and as I mentioned, Ancestry.com has plans to improve this.
Give me the "name, dates, family members" that you typed into the search form. You said they "lived in that same county and state all of their lives, married there, and then died there." If I understand you correctly, you say that the very first results "start out with people who lived 1,000 miles from that location and [were] born 30 years after that person died." Send me the example and I'll make certain it gets to the right people.
Oh, and please don't read through all 24,521 results of a ranked search. When you get that many results in Google you say, "Wow! Google's awesome." But you don't try every single result.
Lastly, I'd like to remind everyone that providing Ancestry.com with detailed, actionable examples is essential to communicating your complaints. Above all, avoid unfounded emotionalism as it distracts from the real problems in New Search.
Thanks,
-- The Ancestry Insider
 NARA has many publications that can help make your research at the archives more productive. Some are available online and some are printed. Of the printed publications, some cost money and some are free.
NARA has many publications that can help make your research at the archives more productive. Some are available online and some are printed. Of the printed publications, some cost money and some are free. Guide to Genealogical Research in the National Archives of the United States, Third Edition.
Guide to Genealogical Research in the National Archives of the United States, Third Edition. 
 Military Service Records at the National Archives, Reference Information Paper (RIP) 109.
Military Service Records at the National Archives, Reference Information Paper (RIP) 109.  Here are three lists that contain publications not all listed above that you might find helpful:
Here are three lists that contain publications not all listed above that you might find helpful:





 I’m a westerner. It doesn’t matter where I go, I rent a car. Out west one can’t so much as stop at a gas station without a car. I doubt I could brush my teeth without a car sitting outside. So after flying into
I’m a westerner. It doesn’t matter where I go, I rent a car. Out west one can’t so much as stop at a gas station without a car. I doubt I could brush my teeth without a car sitting outside. So after flying into  Fare amounts are posted on the vending machine so that you can figure out beforehand how much money to put on the SmarTrip card. If
Fare amounts are posted on the vending machine so that you can figure out beforehand how much money to put on the SmarTrip card. If 

 Archives II
Archives II

